Recursion’s Curse, or When AI Eats AI-Generated Content
I.
Even if ChatGPT and its friends are nowhere near becoming our dreaded Hollywoodian overlords, we might still hand them the keys to humanity’s proverbial kingdom. Especially when it comes to content creation.
But this ushers in a new issue: it has never been easier and cheaper to create (mediocre) content.
Roughly a year ago, Europol released a report in which they warned that by 2026, about 90% of online content might be produced by generative AI tools. Of course, such estimates are as uncertain as they are controversial. Still, I think we can agree that, as long as profit incentives drive the majority of content generation, cheap and easy (and not necessarily nuanced or accurate) will become more prevalent.
Beyond drowning in an ocean of crappy content, what’s so bad about this?
Well, it might make large language models worse. It could even lead to model collapse.
II.
The ChatGPTs of our brave new world are trained on massive amounts of internet-scraped data. But as time goes on and more of the content on the internet is AI-generated, newer GPT generations will inadvertently be trained on content created by their predecessors, rather than content created by humans.
A recent preprint suggests that:
- … use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear.
To make intuitive sense of that, consider this simple normal distribution I cooked up.
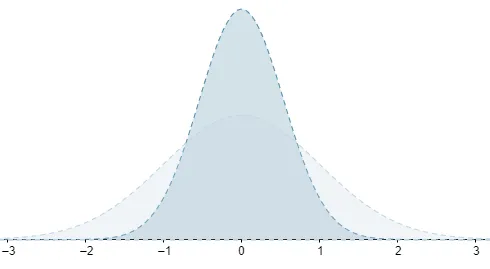
Let’s say perfectly average content (according to whatever metric you want) gets a zero. The further away from zero, the more it deviates from the tyranny of the average. And let’s say human-generated content is the light gray distribution in the back.
In the preprint, the authors suggest that, as more and more AI-generated content makes its way into the training data, this will cut off the tails of the distribution, resulting in something more like the darker, narrower distribution when it comes to generated content.
This, the researchers suggest leads to “model collapse,” which is…
- … a degenerative process affecting generations of learned generative models, where generated data end up polluting the training set of the next generation of models; being trained on polluted data, they then misperceive reality.
After all, large language models don’t care about whether writing (or video, or imagery) is good or bad, or accurate or inaccurate; they simply want to get rid of the outliers.
Automated clickbait, as the authors point out:
- Long-term poisoning attacks on language models are not new. For example, we saw in the creation of click, content, and troll farms a form of human ‘language models’, whose job is to misguide social networks and search algorithms. The negative effect these poisoning attacks had on search results led to changes in search algorithms... What is different with the arrival of LLMs is the scale at which such poisoning can happen once it is automated.
III.
The “can” in that last sentence might even be replaced by “will” now. Another preprint discovered that crowd workers, such as people performing tasks on Amazon Mechanical Turk, are increasingly turning to LLMs to complete their tasks faster, tasks that can include data annotation for... yep, new LLMs.
The preprint’s authors:
- … reran an abstract summarization task from the literature on Amazon Mechanical Turk and, through a combination of keystroke detection and synthetic text classification, estimate that 33-46% of crowd workers used LLMs when completing the task.
Distribution tails are already being chopped off.
This, to me, has quite an Orwellian ring to it. After all,
- Who controls the past controls the future: who controls the present controls the past.
By chopping off the outliers, we’ll not only end up with quickly refreshing bucketloads of average content, but, with every new recursion, that content will be more and more attuned to values and ideologies that initially dominated internet discourse. Image the worst internet troll, amplified with each LLM generation.
There is, however, an interesting corollary to all this: Human-generated data is extremely valuable, even for the business owners and tech bros who are currently pushing human creatives out of work in pursuit of ever more profit.
As the researchers put it:
- The pivotal role of human-generated data in various applications is undeniable. Its richness, uniqueness, and diversity are crucial factors that make it stand apart from synthetically generated data.
*mic drop*
Of course, valuing human-generated data simply for its use in LLM training neglects the intrinsic value of human creative efforts. But even if you are someone who doesn’t care for human creativity beyond squeezing the last drop of profit from it, you’ll benefit from treating and compensating human creators correctly.
Unfortunately, that will require AI developers and power users to look beyond the next hype cycle.
I’m not arguing against AI tools; I am arguing against the use of these tools to quickly generate “meh” content for profit while pushing human creatives (on whose data these models are trained!) out of jobs and relying on woefully underpaid human annotators for the training data. Recently, African workers decided to unionize, seeking protection against monetary exploitation and the mental health burden resulting from their work for ChatGPT, TikTok, and Facebook. Maybe in the next recursion of the AI-generated news cycle, that’s exactly the kind of story that will be chopped off.
This piece was originally published on Thinking Ahead.
